







Agent Kelly, The Appointments Pro
Built for hospitals and clinics, Kelly syncs effortlessly with calendars to schedule, manage, and optimize appointments so your front desk runs itself.
Get Agent KellyPair the top 1% of vetted engineers with production AI agents and ship 3x faster. Same program manager, one SLA, two engines. Engineers in 24 hours from $35 per hour. Agents live in production by tomorrow.

Browse 8,200+ vetted engineers and 4 production AI agents in a single dashboard. Filter by stack, rate, time zone or outcome. Shortlist in minutes. Onboard in 24 hours.
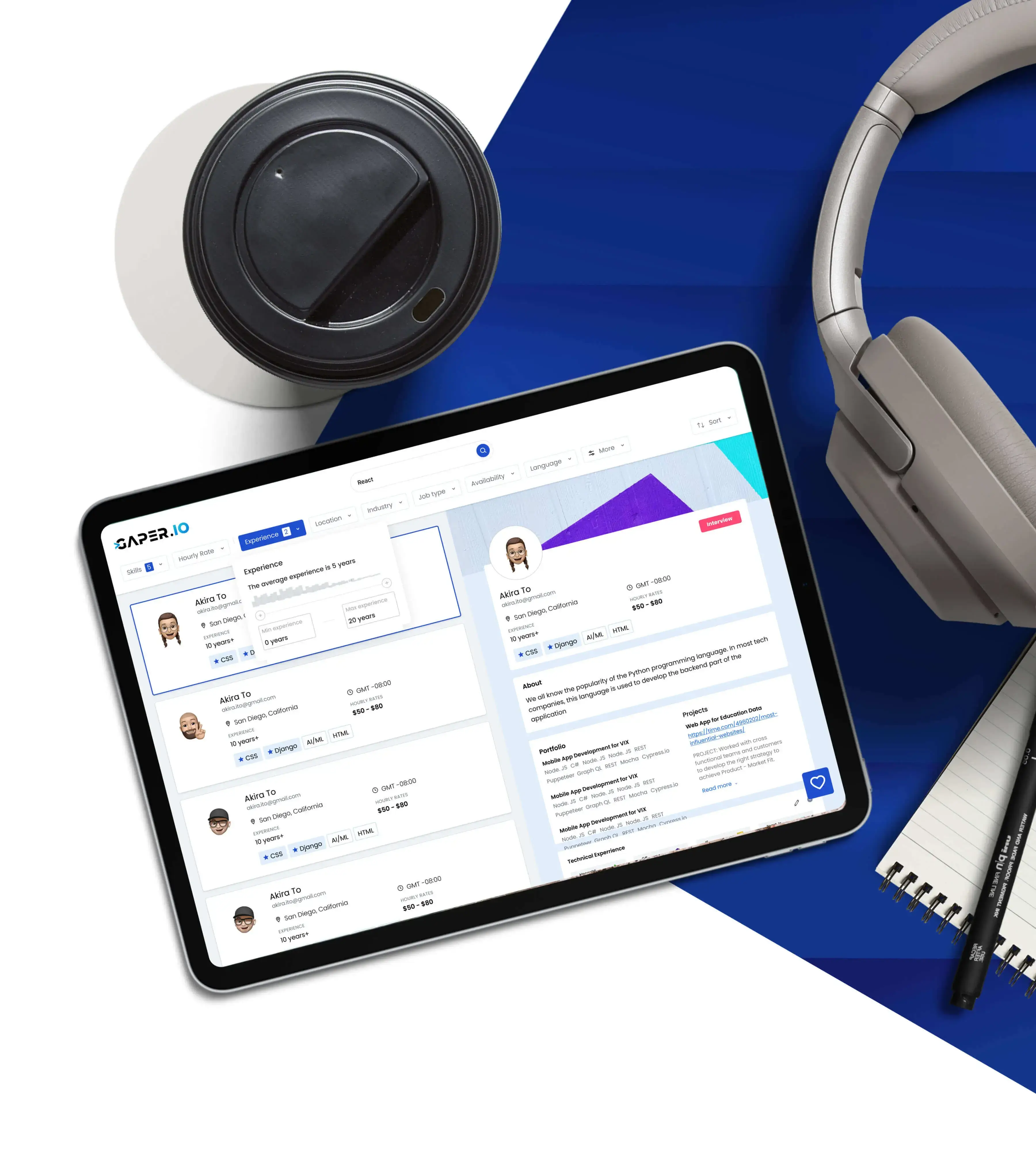
Most platforms force a choice: hire engineers or buy automation. Gaper runs both engines and lets the right one own the work. Today it might be a senior React engineer. Tomorrow it might be Stefan running every campaign while your CMO sleeps.
Pre-vetted on technical depth, communication, and timezone fit. From staff augmentation to full pods. Replaces a US contractor at a third of the cost without the procurement drag.
Kelly, AccountsGPT, James, Stefan. Each is a production agent purpose built for one job. Integrated into your stack and accountable to a metric. Live in 24 hours.
From accountants to coders, these AI agents are built to work smart and help you launch faster. Each agent is trained for a specific role so you always have the right expert on your side without the hiring hassle.
Built for hospitals and clinics, Kelly syncs effortlessly with calendars to schedule, manage, and optimize appointments so your front desk runs itself.
Get Agent Kelly
Your accountant, analyst, and report writer in one. From sales forecasting to report generation, AccountsGPT automates the mundane accounting tasks for you.
Get AccountsGPT
James is your talent scout. Matching CVs, writing accurate and tailored job posts, and helping HR teams hire faster with less guesswork and more precision.
Get Agent James
Stefan plans campaigns, drafts copy, and attributes pipeline so your marketing team ships more in less time. 2.6x content velocity with 38% lower CAC.
Get Agent StefanImprove patient care, streamline clinical workflows, and accelerate service delivery.
Enhance fraud detection, personalize financial services, and optimize risk management.
Automate legal research processes, improve contract analysis, and streamline document review.
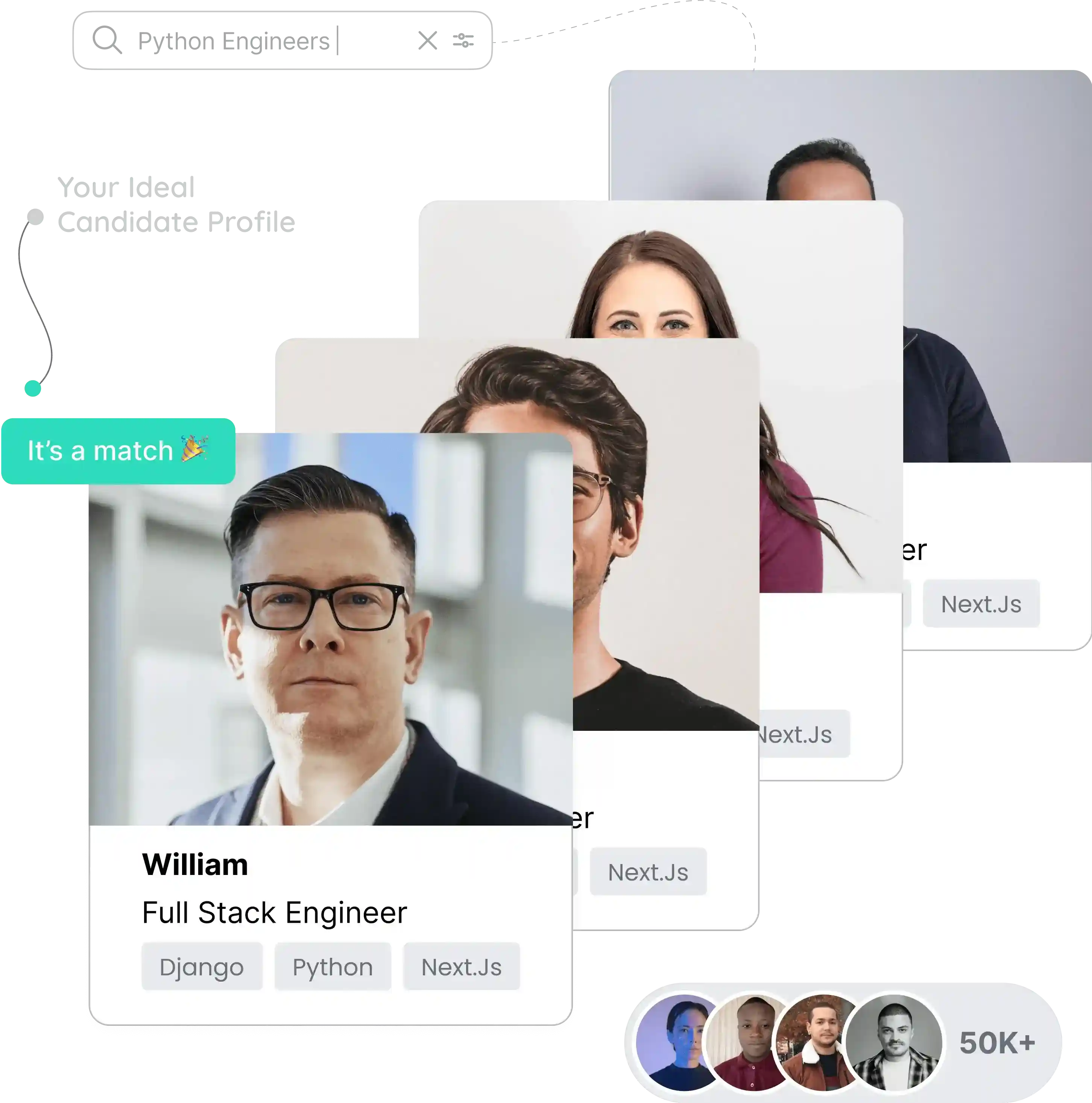
Augment your team with AI engineers or deploy a fully-managed pod to ship and scale production AI systems.






 Python
Python React
React Node.js
Node.js TypeScript
TypeScript MongoDB
MongoDB Postgres
Postgres Next.js
Next.js K8s
K8s Docker
Docker Anthropic
Anthropic LangChain
LangChain HubSpot
HubSpotGaper has been mentioned by many notable magazines




Practical playbooks, hiring frameworks, and AI deployment patterns from the teams scaling with Gaper.
The demand for AI talent has surged by 75% in the past year, making the race to secure top-tier talent more competitive than ever.
No. Most Gaper customers buy both. Engineers handle build out and edge cases. Agents own a recurring workflow. The same US program manager runs the relationship and the SLA.
24 hours for both. Engineers are introduced via shortlist within one business day. Agents go live in shadow mode within 24 hours of a signed scoping doc.
Engineers start at $35 per hour vs Turing $45 to $90 and Andela $65 to $110. Agents start at $1,200 per month, replacing a full headcount that costs $72K to $145K per year.
Yes. Healthcare deployments include BAAs and run inside HIPAA-aligned workflows. Production infrastructure is SOC 2 aligned. US data residency available on request.
Yes. Bring OpenAI, Anthropic, or open weights. Deploy in your VPC, your AWS account, or ours. The agent platform is model-agnostic and infra-agnostic.
Pair top 1% engineers with production AI agents. Ship 3x faster, live in 24 hours, from $35 per hour. One PM, one SLA, one invoice.
Book the assessment








